Contexte
- Pilotage de l’équipe MOE et du Release Management.
- Besoin d’un reporting centralisé et de KPI fiables pour suivre l’activité.
Actions menées
- Mise en place d'un reporting via Microsoft Fabric, Python (Pandas, Spark) et Lakehouse.
- Développement de tableaux de bord interactifs avec Power BI.
Technologies utilisées
Pendant mon stage, j'ai travaillé avec plusieurs technologies pour le pilotage IT et le reporting :
- Python & PySpark : traitement ETL, DataFrames et Delta Lake.
- SQL / Delta SQL : création et historisation de tables dans le Lakehouse.
- Pandas / NumPy : manipulation et transformation des données.
- Power BI : création de rapports et tableaux de bord.
- DAX : calculs avancés pour le reporting analytique.
- Excel : source de données et extraction pour le Lakehouse.
- Fabric : une nouvelle plateforme cloud SaaS complète de données et d’analytique qui permet aux entreprises de collecter, stocker, transformer, analyser et visualiser leurs données dans un environnement unifié.
Conception
Solutions envisagées
Deux solutions principales ont été envisagées pour la mise en place du pilotage :
- Extraction et transformation avec Python + Power BI
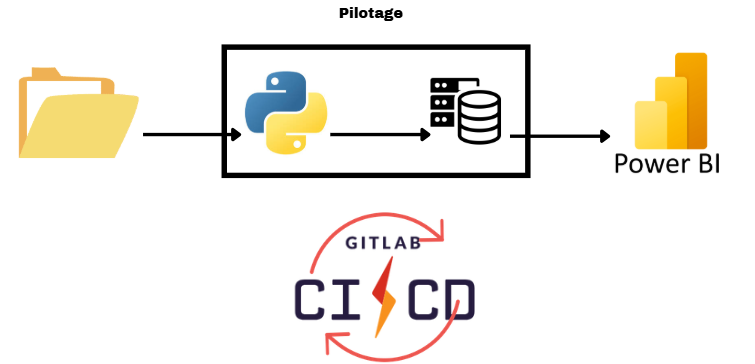
La première solution consistait à utiliser Python pour l'extraction et la transformation des données sur un serveur isolé de l'entreprise, garantissant ainsi la sécurité et la confidentialité des données. Les résultats seraient ensuite visualisés avec Power BI, et l’automatisation assurée par GitLab CI/CD.
Cependant, cette solution impliquait un coût important pour la mise en place du serveur par l’équipe infrastructure et un délai significatif avant d’être opérationnelle.
- Utilisation de Microsoft Fabric
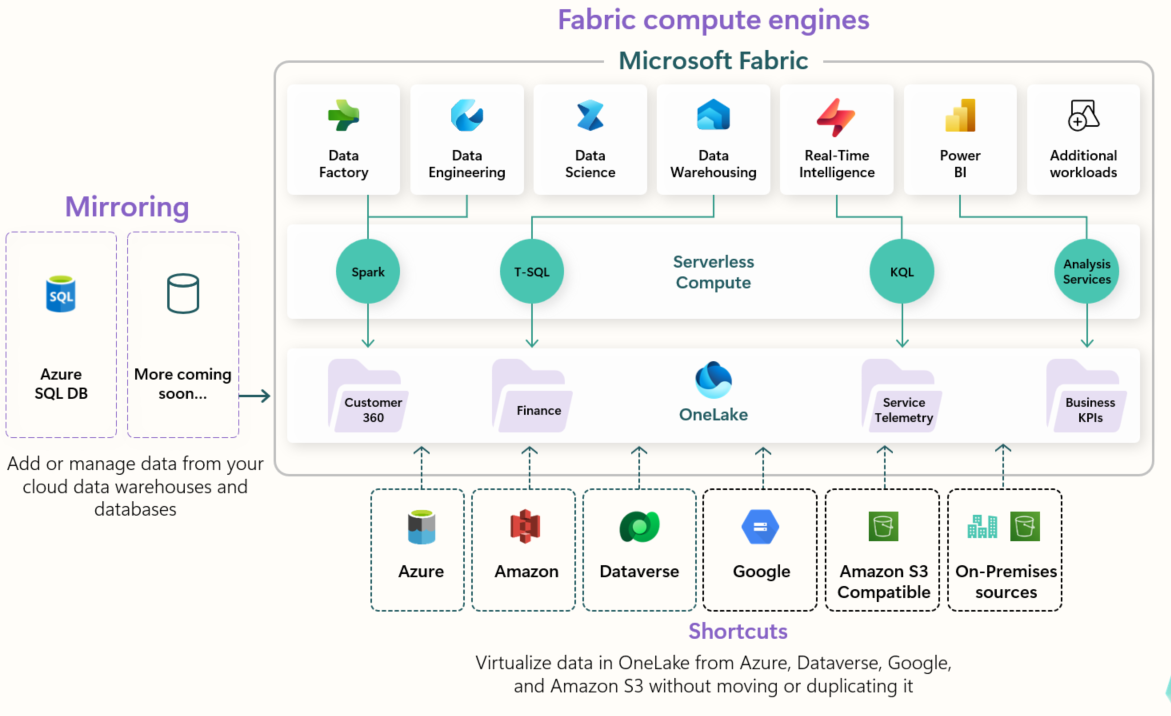
La deuxième solution reposait sur Microsoft Fabric, une plateforme cloud tout-en-un. Bien que les données soient stockées dans le cloud, cela ne pose pas de problème dans ce cas, car elles ne contiennent pas d’informations confidentielles ni de données clients.
Fabric permet d’orchestrer toutes les étapes, de l’extraction à la transformation et la visualisation, sur une seule plateforme. Cela réduit fortement le nombre d’outils nécessaires et permet une mise en place rapide et efficace du traitement. De plus, l'entreprise était déjà intégré à l'environnement Microsoft, il nous a semblé pertinent d'utiliser cette plateforme.
Modèle de données
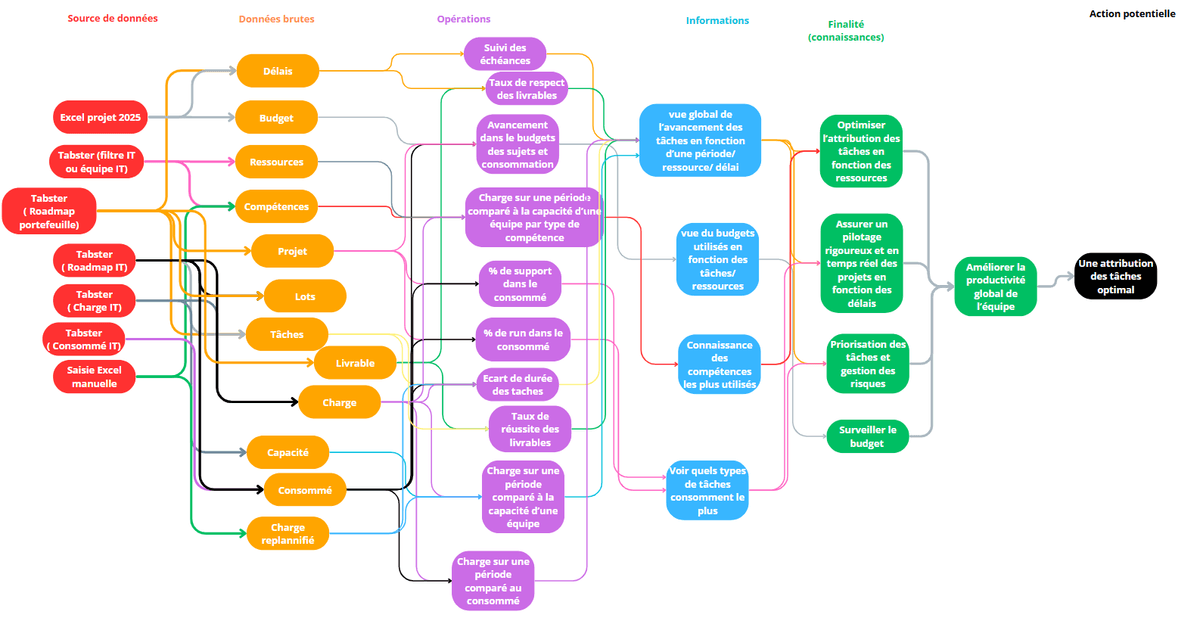
Pour organiser et exploiter les données de manière efficace, nous avons réfléchi à un modèle de données complet pour le Pilotage et le Release Management.
- Flux de données envisagé
Les données sont extraites d'une source principale : des fichiers Excel provenant de Tabsters.
** Extraction **: récupération des fichiers bruts depuis Tabsters.
** Transformation / nettoyage **: uniformisation des formats, parsing des dates, gestion des doublons et enrichissement des données (ex. attribution des compétences aux ressources).
** Chargement **: insertion des données transformées dans les tables du modèle de données final.
** Visualisation** : création de dashboards dans Power BI.
- Modèle en M_etoile
Le modèle de données est conçu selon une architecture en étoile, avec :
Tables faits : Suivi_Charge, Capacite, etc., contenant les mesures principales.
Tables dimensions : Ressource, Competence, Projet, Temps, permettant de filtrer et d’agréger les données facilement.
Cette structure facilite les calculs DAX, l’agrégation et le suivi des indicateurs clés par compétence, action, projet ou période.

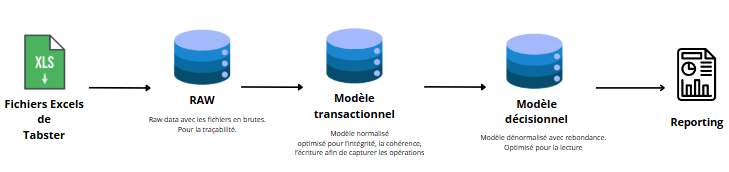
- Base intermédiaire
Initialement, nous avions envisagé de créer une base de données intermédiaire pour stocker les données nettoyées avant de les charger dans le modèle final.
Avantages : isolation des transformations, meilleure traçabilité et possibilité de rejouer les traitements sans toucher aux données sources.
Limitation : avec le volume de données relativement faible pour ce projet, cette couche intermédiaire n’était pas nécessaire, et nous avons donc simplifié le pipeline en chargeant directement les données transformées dans les tables finales.
- Modèles finaux
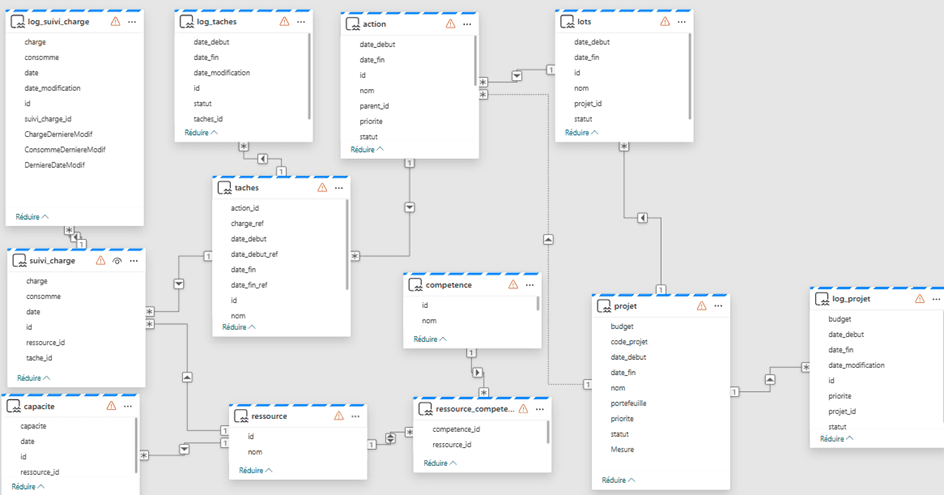
Le modèle de données finalement retenu pour le pilotage:

Le modèle de données finalement retenu pour le release management:
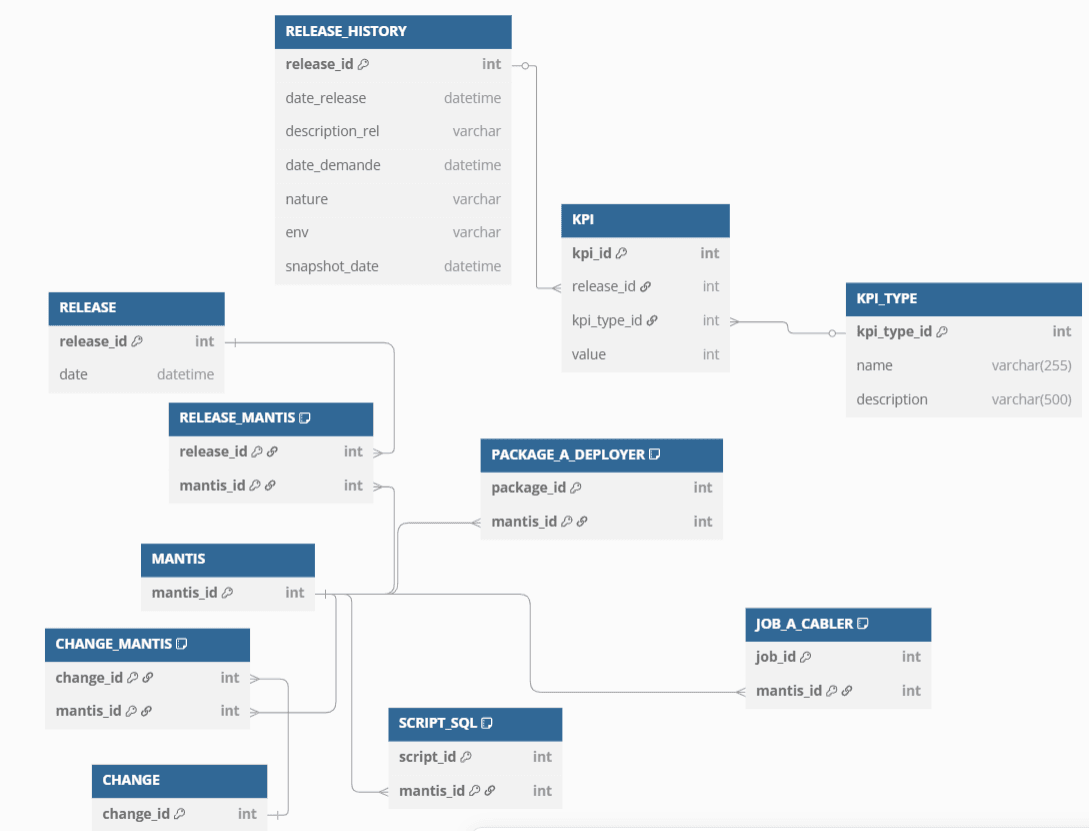
Implémentation
Généralités
Le modèle de la conception a été implémenté sur Fabric, en respectant le modèle en étoile défini lors de la phase de conception. Le modèle comprend les principales tables de faits pour le pilotage, ainsi que leurs tables de dimensions associées, permettant d’effectuer des analyses détaillées tout en conservant une structure lisible et optimisée pour Power BI.
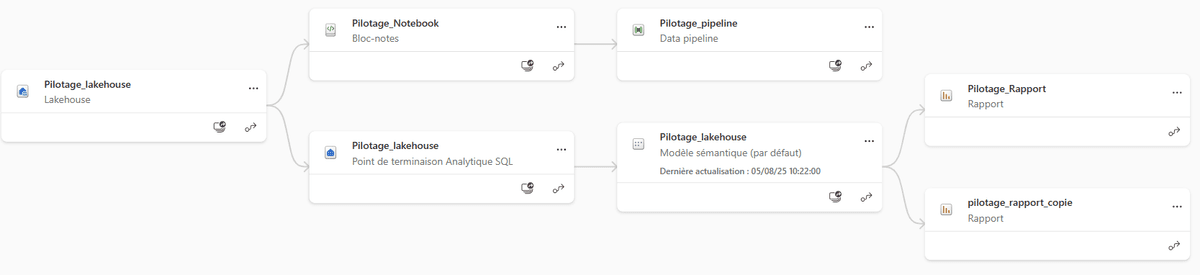
Le flux de données a été entièrement orchestré dans Fabric. Les données sources sont extraites, transformées et consolidées directement dans le pipeline, ce qui permet de suivre chaque étape depuis l’importation jusqu’à la visualisation dans Power BI.
Code
Pour le traitement et la transformation des données, Python/PySpark a été utilisé, en particulier pour sa capacité à gérer des volumes de données importants. Les Delta Tables ont été employées pour permettre des opérations de type upsert, garantissant que les données sont mises à jour ou insérées de manière fiable.
Exemple d’upsert dans une Delta Table :
from delta.tables import DeltaTable
def upsert_table(spark, df_spark, table_name, join_condition):
delta_table = DeltaTable.forName(spark, table_name)
(
delta_table.alias("target")
.merge(df_spark.alias("source"), join_condition)
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
print(f"Upsert terminé pour la table {table_name}")
Lecture et transformation d’un fichier Excel en DataFrame :
import pandas as pd
# Lecture des données
df_raw = pd.read_excel("Export Resources IT - MOE.xlsx")[["Clé de l'objet", "Type de Competence"]].dropna()
# Création des liens ressource ↔ compétence
ressource_competence_data = []
for _, row in df_raw.iterrows():
ressource_id = row["Clé de l'objet"]
competences = [c.strip() for c in str(row["Type de Competence"]).split(",") if c.strip()]
for comp in competences:
ressource_competence_data.append([ressource_id, comp])
Fusion des logs pour assurer un identifiant unique :
from pyspark.sql.functions import col, lit, row_number
from pyspark.sql.window import Window
df_log = df_nouvelles.union(df_modifiees).union(df_supprimees)
window_spec = Window.orderBy("suivi_charge_id")
df_temp = df_log.withColumn("row_num", row_number().over(window_spec))
df_log = df_temp.withColumn("id", lit(max_id) + col("row_num")).drop("row_num")
df_log.write.mode("append").format("delta").saveAsTable("Log_Suivi_Charge")
Dans Power BI, DAX a été utilisé pour créer des mesures calculées à partir du modèle de données final. Ces calculs permettent d’obtenir des indicateurs clés par compétence, par ressource et par type d’action.
Exemple de calcul de capacité et charge par compétence :
CapaciteParCompetence =
SUMX(
FILTER(
ADDCOLUMNS(
CROSSJOIN(capacite, Ressource_Competence),
"NbCompetences",
CALCULATE(
COUNTROWS(Ressource_Competence),
FILTER(
ALL(Ressource_Competence),
Ressource_Competence[ressource_id] = capacite[ressource_id]
)
)
),
capacite[ressource_id] = Ressource_Competence[ressource_id]
),
capacite[capacite] / [NbCompetences]
)
ChargeParCompetence =
SUMX(
FILTER(
ADDCOLUMNS(
CROSSJOIN(Suivi_Charge, Ressource_Competence),
"NbCompetences",
CALCULATE(
COUNTROWS(Ressource_Competence),
FILTER(
ALL(Ressource_Competence),
Ressource_Competence[ressource_id] = Suivi_Charge[ressource_id]
)
)
),
Suivi_Charge[ressource_id] = Ressource_Competence[ressource_id]
),
Suivi_Charge[charge] / [NbCompetences]
)
Exemple de calcul des consommations totales et par type :
Consomme_Total = SUM(Suivi_Charge[consomme])
Consomme_support_technique =
CALCULATE(
SUM(Suivi_Charge[consomme]),
FILTER(taches, taches[action_id] IN { "A196" })
)
Consomme_support_fonctionnel =
CALCULATE(
SUM(Suivi_Charge[consomme]),
FILTER(taches, taches[action_id] IN { "A197" })
)
%_Consomme_technique = DIVIDE([Consomme_support_technique], [Consomme_Total], 0)
%_Consomme_fonctionnel = DIVIDE([Consomme_support_fonctionnel], [Consomme_Total], 0)
Grâce à cette combinaison Fabric + PySpark + Delta + DAX, toutes les étapes du pipeline — extraction, transformation, chargement et visualisation — ont pu être centralisées et automatisées, garantissant des données fiables et des indicateurs mis à jour en temps réel.
Résultats
Toutes ces étapes ont permis de créer un tableau de bord interactif sur Power BI.
Il offre aux utilisateurs une vue complète et dynamique de leurs données, avec la possibilité de filtrer selon leurs besoins (par mois, compétences, personne, etc.).
Par exemple, il est possible de visualiser la répartition des charges afin de mieux les distribuer ensuite:
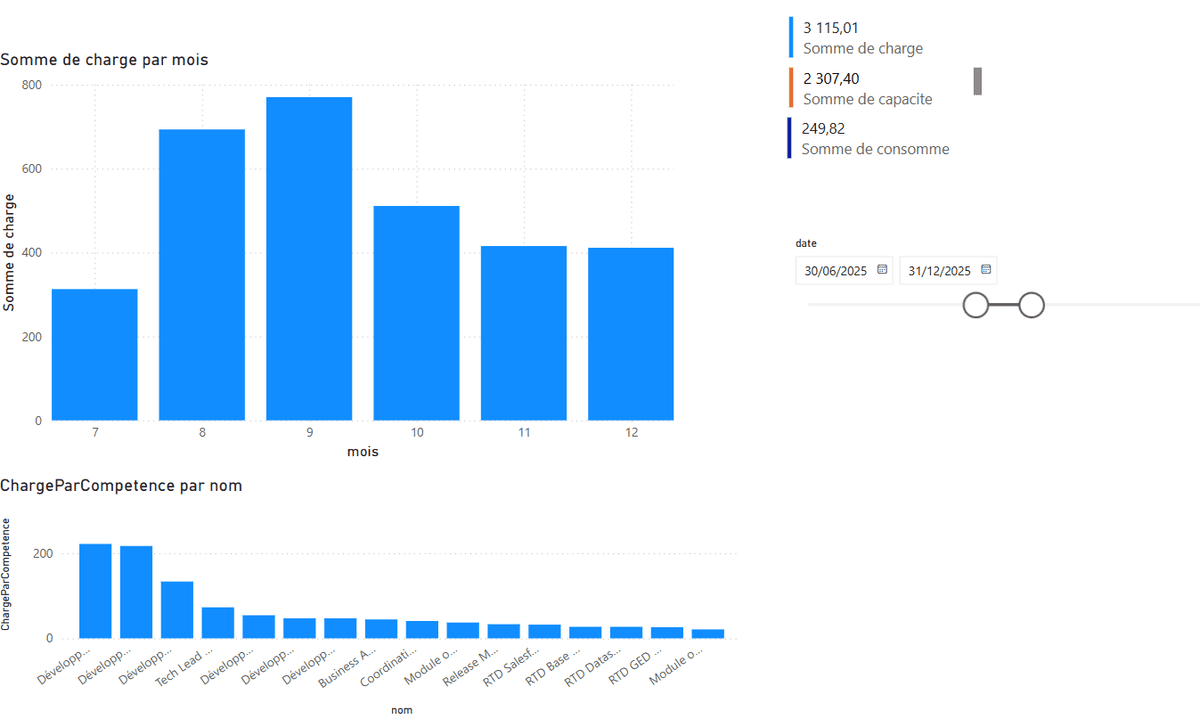
Le tableau de bord permet également de suivre l'évolution des charges consommées dans le temps, ce qui facilite le suivi et la planification des ressources :
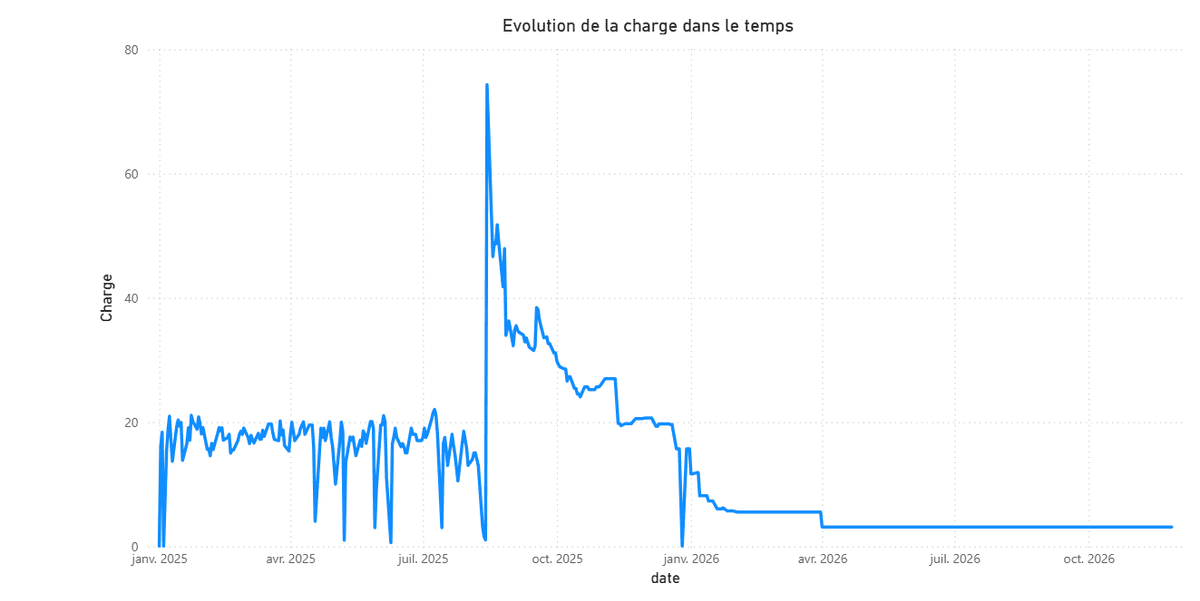
De plus, des indicateurs de performance (KPI) sont directement accessibles, permettant de mesurer l’efficacité du pilotage et d’identifier rapidement les points critiques :
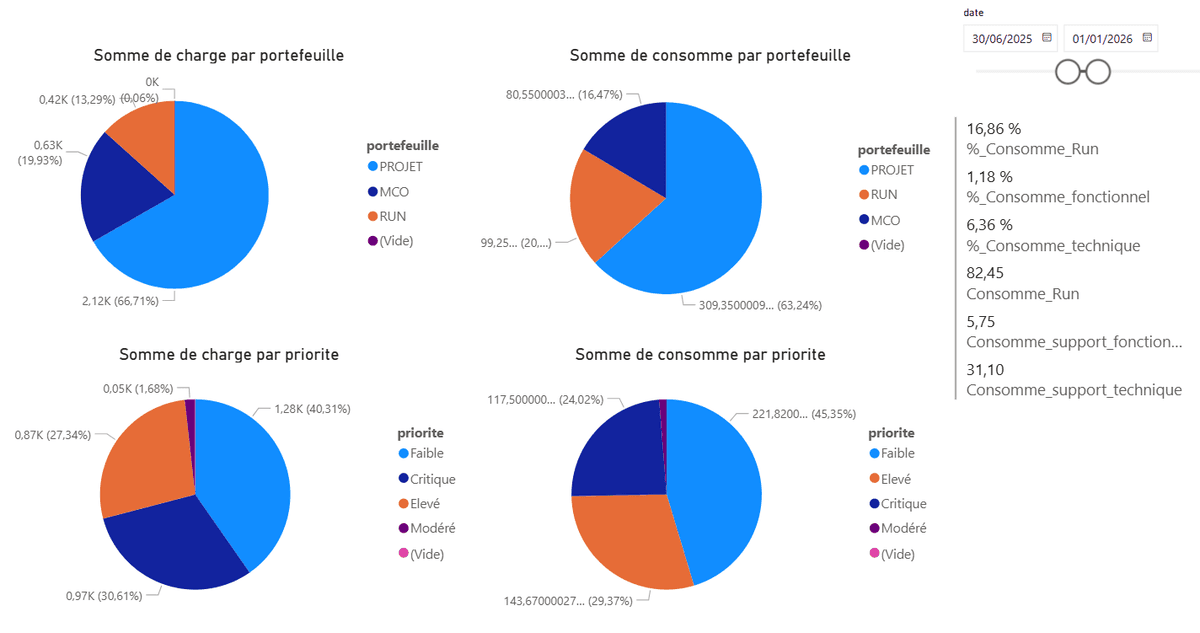
L’un des grands avantages de ce tableau de bord est sa flexibilité : chaque utilisateur peut explorer les données selon ses besoins, filtrer les informations pertinentes et obtenir des analyses adaptées à sa fonction.
Vidéo
Vidéo soutenance orale du stage
Conclusion
La mise en place de ce projet a permis de créer un écosystème complet de pilotage des données allant de l'extraction et de la transformation jusqu'à la visualisation dans Power BI.
Grâce à l'utilisation de Fabric, nous avons pu orchestrer l'ensemble des étapes de traitement de manière centralisée, sécurisée et automatisée, tout en conservant une architecture claire et optimisée. Le modèle en étoile adopté facilite l'analyse et la consultation des données, et les pipelines automatisés assurent la mise à jour continue des informations.
Le tableau de bord final offre aux utilisateurs une vision claire et dynamique des charges et des compétences, avec la possibilité d’adapter les filtres et les indicateurs selon leurs besoins. Cela permet de prendre des décisions plus rapides et mieux informées pour le pilotage des ressources et du suivi des projets.
Enfin, ce projet constitue une base solide pour l'évolution future, avec la possibilité d'intégrer de nouvelles sources de données ou d'ajouter de nouveaux indicateurs selon les besoins des utilisateurs.